Introduction to Knet
![]()



Knet (pronounced "kay-net") is the Koç University deep learning framework implemented in Julia by Deniz Yuret and collaborators. It supports GPU operation and automatic differentiation using dynamic computational graphs for models defined in plain Julia. This document is a tutorial introduction to Knet. Check out the full documentation and Examples for more information. If you use Knet in academic work, here is a paper that can be cited:
@inproceedings{knet2016mlsys,
author={Yuret, Deniz},
title={Knet: beginning deep learning with 100 lines of Julia},
year={2016},
booktitle={Machine Learning Systems Workshop at NIPS 2016}
}Contents
Philosophy
Knet uses dynamic computational graphs generated at runtime for automatic differentiation of (almost) any Julia code. This allows machine learning models to be implemented by defining just the forward calculation (i.e. the computation from parameters and data to loss) using the full power and expressivity of Julia. The implementation can use helper functions, loops, conditionals, recursion, closures, tuples and dictionaries, array indexing, concatenation and other high level language features, some of which are often missing in the restricted modeling languages of static computational graph systems like Theano, Torch, Caffe and Tensorflow. GPU operation is supported by simply using the KnetArray type instead of regular Array for parameters and data.
Knet builds a dynamic computational graph by recording primitive operations during forward calculation. Only pointers to inputs and outputs are recorded for efficiency. Therefore array overwriting is not supported during forward and backward passes. This encourages a clean functional programming style. High performance is achieved using custom memory management and efficient GPU kernels. See Under the hood for more details.
Tutorial
In Knet, a machine learning model is defined using plain Julia code. A typical model consists of a prediction and a loss function. The prediction function takes model parameters and some input, returns the prediction of the model for that input. The loss function measures how bad the prediction is with respect to some desired output. We train a model by adjusting its parameters to reduce the loss. In this section we will see the prediction, loss, and training functions for five models: linear regression, softmax classification, fully-connected, convolutional and recurrent neural networks. It would be best to copy paste and modify these examples on your own computer. You can install Knet using Pkg.add("Knet") in Julia.
Linear regression
Here is the prediction function and the corresponding quadratic loss function for a simple linear regression model:
predict(w,x) = w[1]*x .+ w[2]
loss(w,x,y) = sumabs2(y - predict(w,x)) / size(y,2)The variable w is a list of parameters (it could be a Tuple, Array, or Dict), x is the input and y is the desired output. To train this model, we want to adjust its parameters to reduce the loss on given training examples. The direction in the parameter space in which the loss reduction is maximum is given by the negative gradient of the loss. Knet uses the higher-order function grad from AutoGrad.jl to compute the gradient direction:
using Knet
lossgradient = grad(loss)Note that grad is a higher-order function that takes and returns other functions. The lossgradient function takes the same arguments as loss, e.g. dw = lossgradient(w,x,y). Instead of returning a loss value, lossgradient returns dw, the gradient of the loss with respect to its first argument w. The type and size of dw is identical to w, each entry in dw gives the derivative of the loss with respect to the corresponding entry in w.
Given some training data = [(x1,y1),(x2,y2),...], here is how we can train this model:
function train(w, data; lr=.1)
for (x,y) in data
dw = lossgradient(w, x, y)
for i in 1:length(w)
w[i] -= lr * dw[i]
end
end
return w
endWe simply iterate over the input-output pairs in data, calculate the lossgradient for each example, and move the parameters in the negative gradient direction with a step size determined by the learning rate lr. See Optimization methods for more advanced algorithms.

Let's train this model on the Housing dataset from the UCI Machine Learning Repository.
julia> url = "https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data"
julia> rawdata = readdlm(download(url))
julia> x = rawdata[:,1:13]'
julia> x = (x .- mean(x,2)) ./ std(x,2)
julia> y = rawdata[:,14:14]'
julia> w = Any[ 0.1*randn(1,13), 0 ]
julia> for i=1:10; train(w, [(x,y)]); println(loss(w,x,y)); end
366.0463078055053
...
29.63709385230451The dataset has housing related information for 506 neighborhoods in Boston from 1978. Each neighborhood is represented using 13 attributes such as crime rate or distance to employment centers. The goal is to predict the median value of the houses given in $1000's. After downloading, splitting and normalizing the data, we initialize the parameters randomly and take 10 steps in the negative gradient direction. We can see the loss dropping from 366.0 to 29.6. See housing.jl for more information on this example.
Note that grad was the only function used that is not in the Julia standard library. This is typical of models defined in Knet.
Softmax classification
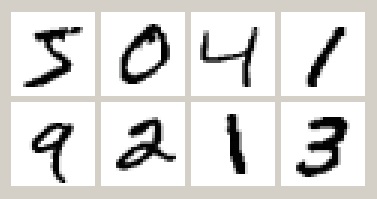
In this example we build a simple classification model for the MNIST handwritten digit recognition dataset. MNIST has 60000 training and 10000 test examples. Each input x consists of 784 pixels representing a 28x28 image. The corresponding output indicates the identity of the digit 0..9.
Classification models handle discrete outputs, as opposed to regression models which handle numeric outputs. We typically use the cross entropy loss function in classification models:
function loss(w,x,ygold)
ypred = predict(w,x)
ynorm = ypred .- log(sum(exp(ypred),1))
-sum(ygold .* ynorm) / size(ygold,2)
endOther than the change of loss function, the softmax model is identical to the linear regression model. We use the same predict, same train and set lossgradient=grad(loss) as before. To see how well our model classifies let's define an accuracy function which returns the percentage of instances classified correctly:
function accuracy(w, data)
ncorrect = ninstance = 0
for (x, ygold) in data
ypred = predict(w,x)
ncorrect += sum(ygold .* (ypred .== maximum(ypred,1)))
ninstance += size(ygold,2)
end
return ncorrect/ninstance
endNow let's train a model on the MNIST data:
julia> include(Knet.dir("examples","mnist.jl"))
julia> using MNIST: xtrn, ytrn, xtst, ytst, minibatch
julia> dtrn = minibatch(xtrn, ytrn, 100)
julia> dtst = minibatch(xtst, ytst, 100)
julia> w = Any[ -0.1+0.2*rand(Float32,10,784), zeros(Float32,10,1) ]
julia> println((:epoch, 0, :trn, accuracy(w,dtrn), :tst, accuracy(w,dtst)))
julia> for epoch=1:10
train(w, dtrn; lr=0.5)
println((:epoch, epoch, :trn, accuracy(w,dtrn), :tst, accuracy(w,dtst)))
end
(:epoch,0,:trn,0.11761667f0,:tst,0.121f0)
(:epoch,1,:trn,0.9005f0,:tst,0.9048f0)
...
(:epoch,10,:trn,0.9196f0,:tst,0.9153f0)Including mnist.jl loads the MNIST data, downloading it from the internet if necessary, and provides a training set (xtrn,ytrn), test set (xtst,ytst) and a minibatch utility which we use to rearrange the data into chunks of 100 instances. After randomly initializing the parameters we train for 10 epochs, printing out training and test set accuracy at every epoch. The final accuracy of about 92% is close to the limit of what we can achieve with this type of model. To improve further we must look beyond linear models.
Multi-layer perceptron
A multi-layer perceptron, i.e. a fully connected feed-forward neural network, is basically a bunch of linear regression models stuck together with non-linearities in between.
We can define a MLP by slightly modifying the predict function:
function predict(w,x)
for i=1:2:length(w)-2
x = max(0, w[i]*x .+ w[i+1])
end
return w[end-1]*x .+ w[end]
endHere w[2k-1] is the weight matrix and w[2k] is the bias vector for the k'th layer. max(0,a) implements the popular rectifier non-linearity. Note that if w only has two entries, this is equivalent to the linear and softmax models. By adding more entries to w, we can define multi-layer perceptrons of arbitrary depth. Let's define one with a single hidden layer of 64 units:
w = Any[ -0.1+0.2*rand(Float32,64,784), zeros(Float32,64,1),
-0.1+0.2*rand(Float32,10,64), zeros(Float32,10,1) ]The rest of the code is the same as the softmax model. We use the same cross-entropy loss function and the same training script. The code for this example is available in mnist.jl. The multi-layer perceptron does significantly better than the softmax model:
(:epoch,0,:trn,0.10166667f0,:tst,0.0977f0)
(:epoch,1,:trn,0.9389167f0,:tst,0.9407f0)
...
(:epoch,10,:trn,0.9866f0,:tst,0.9735f0)Convolutional neural network
To improve the performance further, we can use a convolutional neural networks (CNN). See the course notes by Andrej Karpathy for a good introduction to CNNs. We will implement the LeNet model which consists of two convolutional layers followed by two fully connected layers.
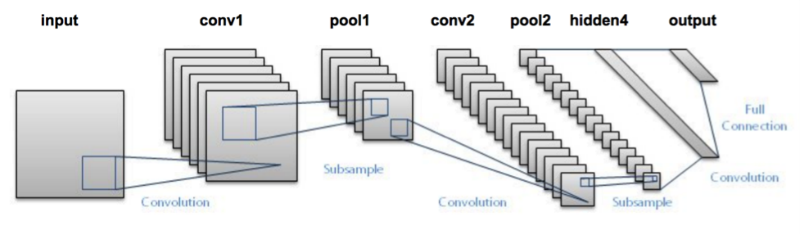
Knet provides the conv4 and pool functions for the implementation of convolutional nets:
function predict(w,x0)
x1 = pool(max(0, conv4(w[1],x0) .+ w[2]))
x2 = pool(max(0, conv4(w[3],x1) .+ w[4]))
x3 = max(0, w[5]*mat(x2) .+ w[6])
return w[7]*x3 .+ w[8]
endThe weights for the convolutional net can be initialized as follows:
w = Any[ -0.1+0.2*rand(Float32,5,5,1,20), zeros(Float32,1,1,20,1),
-0.1+0.2*rand(Float32,5,5,20,50), zeros(Float32,1,1,50,1),
-0.1+0.2*rand(Float32,500,800), zeros(Float32,500,1),
-0.1+0.2*rand(Float32,10,500), zeros(Float32,10,1) ]Currently convolution and pooling are only supported on the GPU for 4-D and 5-D arrays. So we reshape our data and transfer it to the GPU along with the parameters by converting them into KnetArrays:
dtrn = map(d->(KnetArray(reshape(d[1],(28,28,1,100))), KnetArray(d[2])), dtrn)
dtst = map(d->(KnetArray(reshape(d[1],(28,28,1,100))), KnetArray(d[2])), dtst)
w = map(KnetArray, w)The training proceeds as before giving us even better results. The code for the LeNet example can be found in lenet.jl.
(:epoch,0,:trn,0.12215f0,:tst,0.1263f0)
(:epoch,1,:trn,0.96963334f0,:tst,0.971f0)
...
(:epoch,10,:trn,0.99553335f0,:tst,0.9879f0)Recurrent neural network
In this section we will see how to implement a recurrent neural network (RNN) in Knet. An RNN is a class of neural network where connections between units form a directed cycle, which allows them to keep a persistent state over time. This gives them the ability to process sequences of arbitrary length one element at a time, while keeping track of what happened at previous elements.
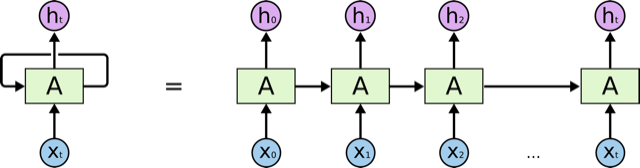
As an example, we will build a character-level language model inspired by "The Unreasonable Effectiveness of Recurrent Neural Networks" from the Andrej Karpathy blog. The model can be trained with different genres of text, and can be used to generate original text in the same style.
It turns out simple RNNs are not very good at remembering things for a very long time. Currently the most popular solution is to use a more complicated unit like the Long Short Term Memory (LSTM). An LSTM controls the information flow into and out of the unit using gates similar to digital circuits and can model long term dependencies. See Understanding LSTM Networks by Christopher Olah for a good overview of LSTMs.
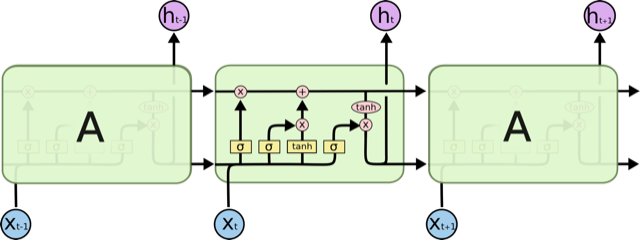
The code below shows one way to define an LSTM in Knet. The first two arguments are the parameters, the weight matrix and the bias vector. The next two arguments hold the internal state of the LSTM: the hidden and cell arrays. The last argument is the input. Note that for performance reasons we lump all the parameters of the LSTM into one matrix-vector pair instead of using separate parameters for each gate. This way we can perform a single matrix multiplication, and recover the gates using array indexing. We represent input, hidden and cell as row vectors rather than column vectors for more efficient concatenation and indexing. sigm and tanh are the sigmoid and the hyperbolic tangent activation functions. The LSTM returns the updated state variables hidden and cell.
function lstm(weight,bias,hidden,cell,input)
gates = hcat(input,hidden) * weight .+ bias
hsize = size(hidden,2)
forget = sigm(gates[:,1:hsize])
ingate = sigm(gates[:,1+hsize:2hsize])
outgate = sigm(gates[:,1+2hsize:3hsize])
change = tanh(gates[:,1+3hsize:end])
cell = cell .* forget + ingate .* change
hidden = outgate .* tanh(cell)
return (hidden,cell)
endThe LSTM has an input gate, forget gate and an output gate that control information flow. Each gate depends on the current input value, and the last hidden state hidden. The memory value cell is computed by blending a new value change with the old cell value under the control of input and forget gates. The output gate decides how much of the cell is shared with the outside world.
If an input gate element is close to 0, the corresponding element in the new input will have little effect on the memory cell. If a forget gate element is close to 1, the contents of the corresponding memory cell can be preserved for a long time. Thus the LSTM has the ability to pay attention to the current input, or reminisce in the past, and it can learn when to do which based on the problem.
To build a language model, we need to predict the next character in a piece of text given the current character and recent history as encoded in the internal state. The predict function below implements a multi-layer LSTM model. s[2k-1:2k] hold the hidden and cell arrays and w[2k-1:2k] hold the weight and bias parameters for the k'th LSTM layer. The last three elements of w are the embedding matrix and the weight/bias for the final prediction. predict takes the current character encoded in x as a one-hot row vector, multiplies it with the embedding matrix, passes it through a number of LSTM layers, and converts the output of the final layer to the same number of dimensions as the input using a linear transformation. The state variable s is modified in-place.
function predict(w, s, x)
x = x * w[end-2]
for i = 1:2:length(s)
(s[i],s[i+1]) = lstm(w[i],w[i+1],s[i],s[i+1],x)
x = s[i]
end
return x * w[end-1] .+ w[end]
endTo train the language model we will use Backpropagation Through Time (BPTT) which basically means running the network on a given sequence and updating the parameters based on the total loss. Here is a function that calculates the total cross-entropy loss for a given (sub)sequence:
function loss(param,state,sequence,range=1:length(sequence)-1)
total = 0.0; count = 0
atype = typeof(getval(param[1]))
input = convert(atype,sequence[first(range)])
for t in range
ypred = predict(param,state,input)
ynorm = logp(ypred,2) # ypred .- log(sum(exp(ypred),2))
ygold = convert(atype,sequence[t+1])
total += sum(ygold .* ynorm)
count += size(ygold,1)
input = ygold
end
return -total / count
endHere param and state hold the parameters and the state of the model, sequence and range give us the input sequence and a possible range over it to process. We convert the entries in the sequence to inputs that have the same type as the parameters one at a time (to conserve GPU memory). We use each token in the given range as an input to predict the next token. The average cross-entropy loss per token is returned.
To generate text we sample each character randomly using the probabilities predicted by the model based on the previous character:
function generate(param, state, vocab, nchar)
index_to_char = Array(Char, length(vocab))
for (k,v) in vocab; index_to_char[v] = k; end
input = oftype(param[1], zeros(1,length(vocab)))
index = 1
for t in 1:nchar
ypred = predict(param,state,input)
input[index] = 0
index = sample(exp(logp(ypred)))
print(index_to_char[index])
input[index] = 1
end
println()
endHere param and state hold the parameters and state variables as usual. vocab is a Char-\>Int dictionary of the characters that can be produced by the model, and nchar gives the number of characters to generate. We initialize the input as a zero vector and use predict to predict subsequent characters. sample picks a random index based on the normalized probabilities output by the model.
At this point we can train the network on any given piece of text (or other discrete sequence). For efficiency it is best to minibatch the training data and run BPTT on small subsequences. See charlm.jl for details. Here is a sample run on 'The Complete Works of William Shakespeare':
$ cd .julia/Knet/examples
$ wget http://www.gutenberg.org/files/100/100.txt
$ julia charlm.jl --data 100.txt --epochs 10 --winit 0.3 --save shakespeare.jld
... takes about 10 minutes on a GPU machine
$ julia charlm.jl --load shakespeare.jld --generate 1000
Pand soping them, my lord, if such a foolish?
MARTER. My lord, and nothing in England's ground to new comp'd.
To bless your view of wot their dullst. If Doth no ape;
Which with the heart. Rome father stuff
These shall sweet Mary against a sudden him
Upon up th' night is a wits not that honour,
Shouts have sure?
MACBETH. Hark? And, Halcance doth never memory I be thou what
My enties mights in Tim thou?
PIESTO. Which it time's purpose mine hortful and
is my Lord.
BOTTOM. My lord, good mine eyest, then: I will not set up.
LUCILIUS. Who shallBenchmarks
Each of the examples above was used as a benchmark to compare Knet with other frameworks. The table below shows the number of seconds it takes to train a given model for a particular dataset, number of epochs and minibatch size for Knet, Theano, Torch, Caffe and TensorFlow. Knet has comparable performance to other commonly used frameworks.
| model | dataset | epochs | batch | Knet | Theano | Torch | Caffe | TFlow |
|---|---|---|---|---|---|---|---|---|
| LinReg | Housing | 10K | 506 | 2.84 | 1.88 | 2.66 | 2.35 | 5.92 |
| Softmax | MNIST | 10 | 100 | 2.35 | 1.40 | 2.88 | 2.45 | 5.57 |
| MLP | MNIST | 10 | 100 | 3.68 | 2.31 | 4.03 | 3.69 | 6.94 |
| LeNet | MNIST | 1 | 100 | 3.59 | 3.03 | 1.69 | 3.54 | 8.77 |
| CharLM | Hiawatha | 1 | 128 | 2.25 | 2.42 | 2.23 | 1.43 | 2.86 |
The benchmarking was done on g2.2xlarge GPU instances on Amazon AWS. The code is available at github and as machine image deep_AMI_v6 at AWS N.California. See the section on Using Amazon AWS for more information. The datasets are available online using the following links: Housing, MNIST, Hiawatha. The MLP uses a single hidden layer of 64 units. CharLM uses a single layer LSTM language model with embedding and hidden layer sizes set to 256 and trained using BPTT with a sequence length of 100. Each dataset was minibatched and transferred to GPU prior to benchmarking when possible.
Under the hood
Knet relies on the AutoGrad package and the KnetArray data type for its functionality and performance. AutoGrad computes the gradient of Julia functions and KnetArray implements high performance GPU arrays with custom memory management. This section briefly describes them.
KnetArrays
GPUs have become indispensable for training large deep learning models. Even the small examples implemented here run up to 17x faster on the GPU compared to the 8 core CPU architecture we use for benchmarking. However GPU implementations have a few potential pitfalls: (i) GPU memory allocation is slow, (ii) GPU-RAM memory transfer is slow, (iii) reduction operations (like sum) can be very slow unless implemented properly (See Optimizing Parallel Reduction in CUDA).
Knet implements KnetArray as a Julia data type that wraps GPU array pointers. KnetArray is based on the more standard CudaArray with a few important differences: (i) KnetArrays have a custom memory manager, similar to ArrayFire, which reuse pointers garbage collected by Julia to reduce the number of GPU memory allocations, (ii) array ranges (e.g. a[:,3:5]) are handled as views with shared pointers instead of copies when possible, and (iii) a number of custom CUDA kernels written for KnetArrays implement element-wise, broadcasting, and scalar and vector reduction operations efficiently. As a result Knet allows users to implement their models using high-level code, yet be competitive in performance with other frameworks as demonstrated in the benchmarks section.
AutoGrad
As we have seen, many common machine learning models can be expressed as differentiable programs that input parameters and data and output a scalar loss value. The loss value measures how close the model predictions are to desired values with the given parameters. Training a model can then be seen as an optimization problem: find the parameters that minimize the loss. Typically, a gradient based optimization algorithm is used for computational efficiency: the direction in the parameter space in which the loss reduction is maximum is given by the negative gradient of the loss with respect to the parameters. Thus gradient computations take a central stage in software frameworks for machine learning. In this section I will briefly outline existing gradient computation techniques and motivate the particular approach taken by Knet.
Computation of gradients in computer models is performed by four main methods (Baydin et al. 2015):
manual differentiation (programming the derivatives)
numerical differentiation (using finite difference approximations)
symbolic differentiation (using expression manipulation)
automatic differentiation (detailed below)
Manually taking derivatives and coding the result is labor intensive, error-prone, and all but impossible with complex deep learning models. Numerical differentiation is simple: $f'(x)=(f(x+\epsilon)-f(x-\epsilon))/(2\epsilon)$ but impractical: the finite difference equation needs to be evaluated for each individual parameter, of which there are typically many. Pure symbolic differentiation using expression manipulation, as implemented in software such as Maxima, Maple, and Mathematica is impractical for different reasons: (i) it may not be feasible to express a machine learning model as a closed form mathematical expression, and (ii) the symbolic derivative can be exponentially larger than the model itself leading to inefficient run-time calculation. This leaves us with automatic differentiation.
Automatic differentiation is the idea of using symbolic derivatives only at the level of elementary operations, and computing the gradient of a compound function by applying the chain rule to intermediate numerical results. For example, pure symbolic differentiation of $\sin^2(x)$ could give us $2\sin(x)\cos(x)$ directly. Automatic differentiation would use the intermediate numerical values $x_1=\sin(x)$, $x_2=x_1^2$ and the elementary derivatives $dx_2/dx_1=2x_1$, $dx_1/dx=\cos(x)$ to compute the same answer without ever building a full gradient expression.
To implement automatic differentiation the target function needs to be decomposed into its elementary operations, a process similar to compilation. Most machine learning frameworks (such as Theano, Torch, Caffe, Tensorflow and older versions of Knet prior to v0.8) compile models expressed in a restricted mini-language into a static computational graph of elementary operations that have pre-defined derivatives. There are two drawbacks with this approach: (i) the restricted mini-languages tend to have limited support for high-level language features such as conditionals, loops, helper functions, array indexing, etc. (e.g. the infamous scan operation in Theano) (ii) the sequence of elementary operations that unfold at run-time needs to be known in advance, and they are difficult to handle when the sequence is data dependent.
There is an alternative: high-level languages, like Julia and Python, already know how to decompose functions into their elementary operations. If we let the users define their models directly in a high-level language, then record the elementary operations during loss calculation at run-time, a dynamic computational graph can be constructed from the recorded operations. The cost of recording is not prohibitive: The table below gives cumulative times for elementary operations of an MLP with quadratic loss. Recording only adds 15% to the raw cost of the forward computation. Backpropagation roughly doubles the total time as expected.
| op | secs |
|---|---|
a1=w1*x | 0.67 |
a2=w2.+a1 | 0.71 |
a3=max(0,a2) | 0.75 |
a4=w3*a3 | 0.81 |
a5=w4.+a4 | 0.85 |
a6=a5-y | 0.89 |
a7=sumabs2(a6) | 1.18 |
| +recording | 1.33 |
| +backprop | 2.79 |
This is the approach taken by the popular autograd Python package and its Julia port AutoGrad.jl used by Knet. Recently, other machine learning frameworks have been adapting dynamic computational graphs: Chainer, DyNet, PyTorch, TensorFlow Fold.
In Knet g=grad(f) generates a gradient function g, which takes the same inputs as the function f but returns the gradient. The gradient function g triggers recording by boxing the parameters in a special data type and calls f. The elementary operations in f are overloaded to record their actions and output boxed answers when their inputs are boxed. The sequence of recorded operations is then used to compute gradients. In the Julia AutoGrad package, derivatives can be defined independently for each method of a function (determined by argument types) making full use of Julia's multiple dispatch. New elementary operations and derivatives can be defined concisely using Julia's macro and meta-programming facilities. See AutoGrad.jl for details.
Contributing
Knet is an open-source project and we are always open to new contributions: bug reports and fixes, feature requests and contributions, new machine learning models and operators, inspiring examples, benchmarking results are all welcome. If you need help or would like to request a feature, please consider joining the knet-users mailing list. If you find a bug, please open a GitHub issue. If you would like to contribute to Knet development, check out the knet-dev mailing list and Tips for developers.
Current contributors:
Deniz Yuret
Ozan Arkan Can
Onur Kuru
Emre Ünal
Erenay Dayanık
Ömer Kırnap
İlker Kesen
Emre Yolcu
Meriç Melike Softa
Ekrem Emre Yurdakul